该系列为南京大学课程《用Python玩转数据》学习笔记,主要以思维导图的记录
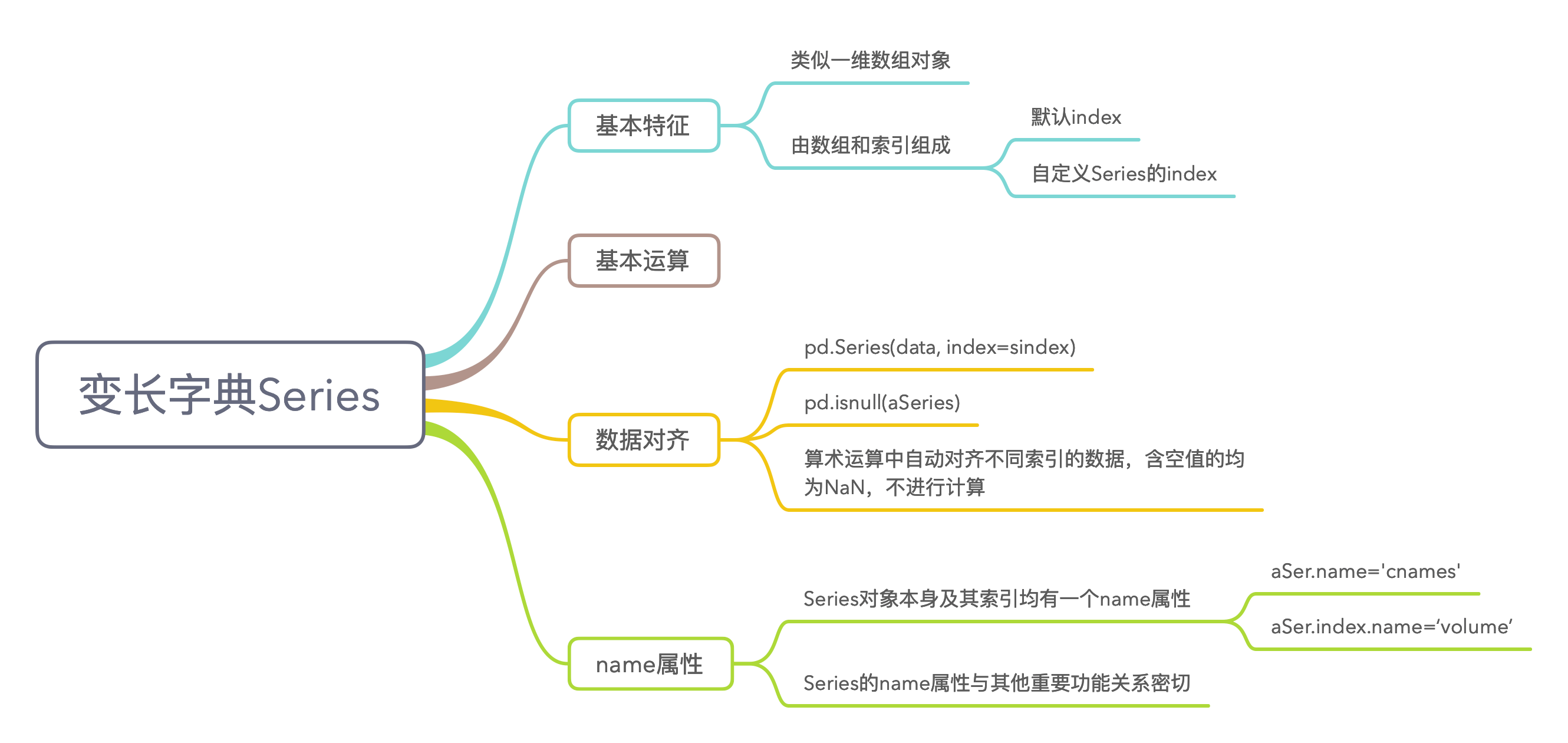
4.6 变长字典Series
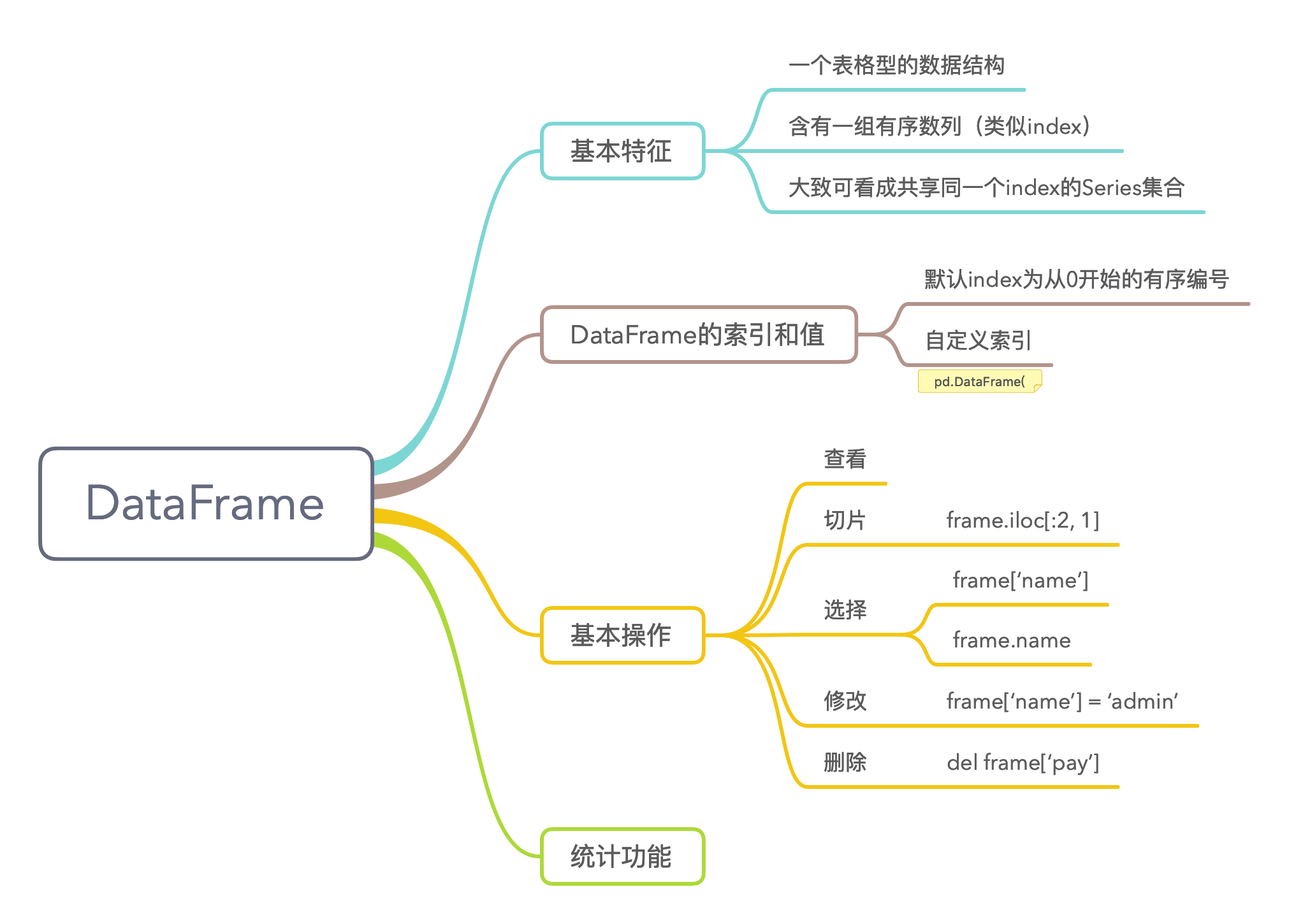
4.7 DataFrame
创建DataFrame小练习
已知有一个列表中存放了一组音乐数据:
music_data = [(“the rolling stones”,”Satisfaction”),(“Beatles”,”Let It Be”),(“Guns N’ Roses”,”Don’t Cry”),(“Metallica”,”Nothing Else Matters”)]
请根据这组数据创建一个如下的 DataFrame:
1 | singer song_name |
实现:
1 | import pandas as pd |
字典相关编程题
1. 找人程序
题目内容:
有5名某界大佬xiaoyun、xiaohong、xiaoteng、xiaoyi和xiaoyang,其QQ号分别是88888、5555555、11111、12341234和1212121,用字典将这些数据组织起来。编程实现以下功能:用户输入某一个大佬的姓名后输出其QQ号,如果输入的姓名不在字典中则输出字符串“Not Found”。
输入格式:
字符串
输出格式:
字符串
输入样例:
xiaoyun
输出样例:
88888
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def find_person(dict_users, strU):
if strU in dict_users:
return dict_users[strU]
else:
return 'Not Found'
if __name__ == "__main__":
dict_users = {
'xiaoyun': '88888',
'xiaohong': '5555555',
'xiaoteng': '11111',
'xiaoyang': '12341234',
'xiaoyi': '1212121'
}
strU = input()
print(find_person(dict_users, strU))2.统计句子中的词频
题目内容:
对于一个已分词的句子(可方便地扩展到统计文件中的词频):
我/是/一个/测试/句子/,/大家/赶快/来/统计/我/吧/,/大家/赶快/来/统计/我/吧/,/大家/赶快/来/统计/我/吧/,/重要/事情/说/三遍/!
可以用collections模块中的Counter()函数方便地统计词频,例如可用如下代码:
1
2
3
4
5
6
7import collections
import copy
s = "我/是/一个/测试/句子/,/大家/赶快/来/统计/我/吧/,/大家/赶快/来/统计/我/吧/,/大家/赶快/来/统计/我/吧/,/重要/事情/说/三遍/!/"
s_list = s.split('/')
# 为避免迭代时修改迭代对象本身,创建一个列表的深拷贝,也可用浅拷贝s_list_backup = s_list[:]
s_list_backup = copy.deepcopy(s_list)
[s_list.remove(item) for item in s_list_backup if item in ',。!”“']输入格式:
字符串
输出格式:
整数
输入样例(因为oj系统限制,测试用例设为判断英文单词个数(不区分大小写,全部转换成小写字符处理),请注意英文标点,假设仅包含,和.):
not
输出样例:
2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def countfeq(s):
out = {}
words = s.split()
for word in words:
if word[-1] in [',', '.', ')', ':']:
word = word[:-1]
out[word] = out.get(word, 0) + 1
return out
if __name__ == "__main__":
s = "Not clumsy person in this world, only lazy people, only people can not hold out until the last."
s_dict = countfeq(s.lower())
word = input()
print(s_dict.get(word, 0))
