背景
最近几年猫眼电影越来越热门了,都差不多和豆瓣并驾齐驱了。今年的《流浪地球》这么火,看看猫眼电影上网友对该片的评价如何。
思路
找到评论网页地址
先打开猫眼官网找到《流浪地球》的介绍页面:https://maoyan.com/films/248906
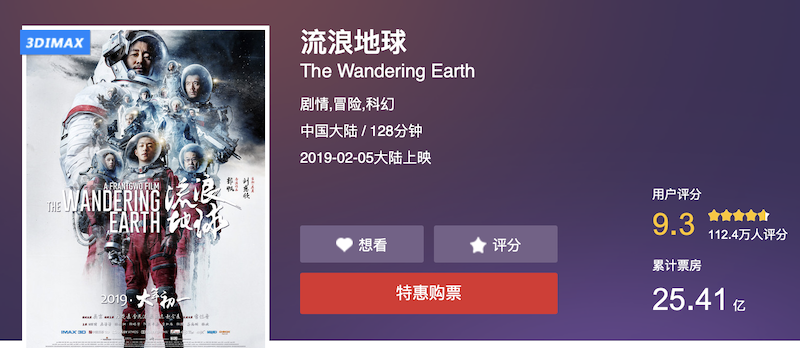
虽然显示有112.4万人评分,但是页面只有热门短评,其他评论都去哪里了,手机明明是有的。
那么我们用chrome切换到手机页面:
- 打开开发者工具
- 开启手机浏览功能
- 访问手机版地址:http://m.maoyan.com/movie/248906?_v_=yes&channelId=4&$from=canary#
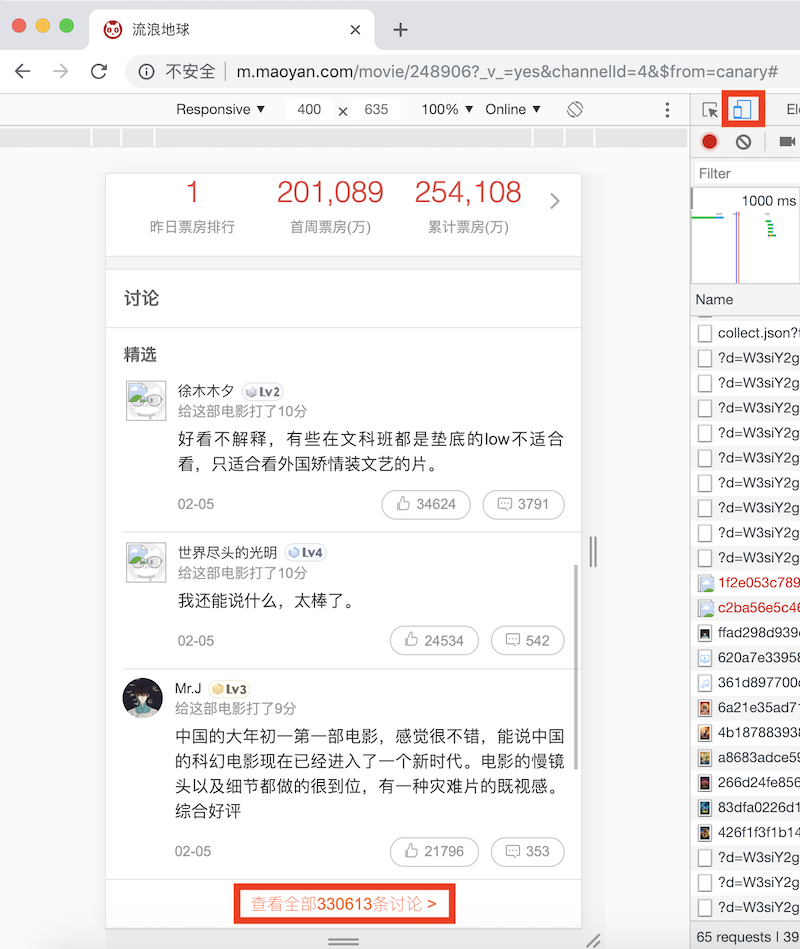
这时候我们就看到了所有的评论。
获取评论请求地址
在点击打开“查看全部330613条讨论”后,发现评论分为最热和最新两部分,最热数量有限,而最新则是未经过处理的,也正是我们需要的。通过search来查看下对应的请求:
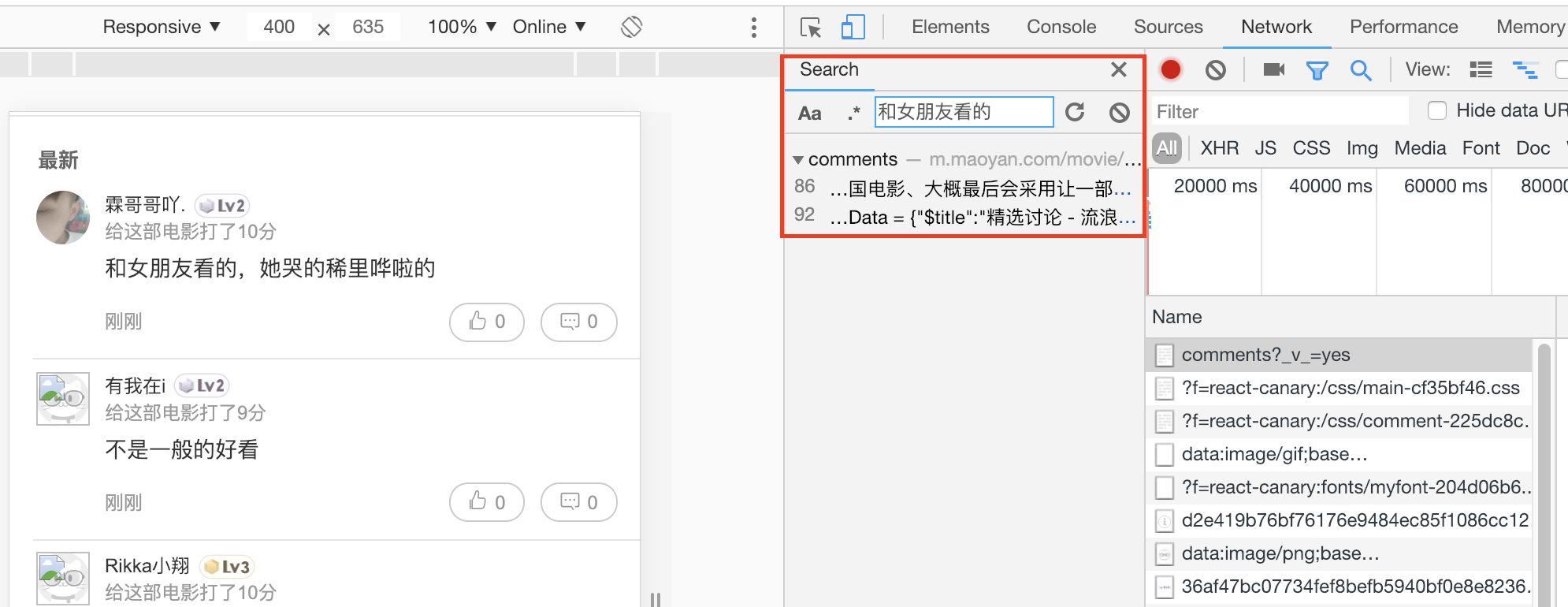
发现,在chrome 的网络展示中发现只有一个类型为document的请求包含了所需的信息。那么这部分的评论获取就需要解析网页了,我们再把屏幕上的评论往下拉,发现会自动加载更多的评论,对应的chrome网络请求多出来了两个comments.json的请求:
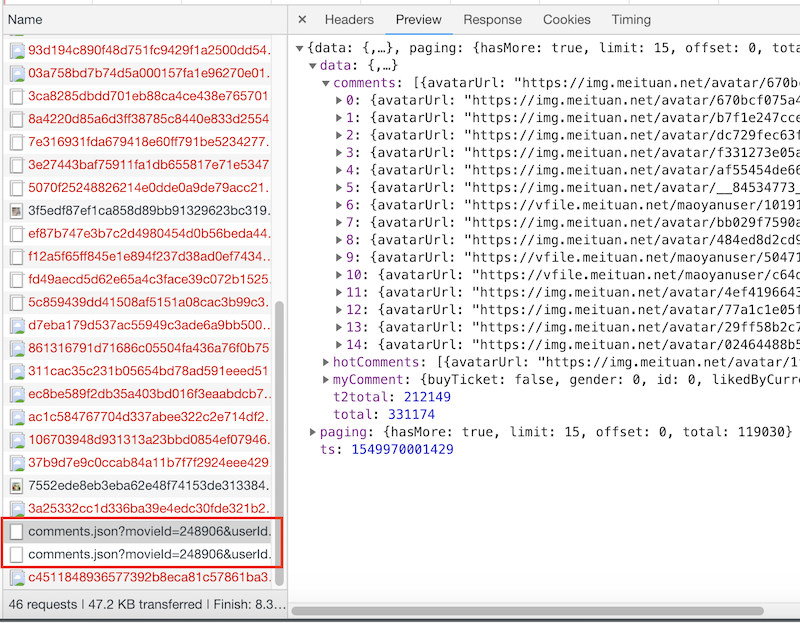
果然这才是我们需要的!把初始页面的url和这两个json请求的url复制到一起比较一下:
1 | http://m.maoyan.com/review/v2/comments.json?movieId=248906&userId=-1&offset=0&limit=15&ts=0&type=3 |
我们可以发现规律:
初始页面的
ts值为0,随后会有ts值,且保持不变。这里的ts是当前的时间戳,可以通过转换工具查看:
offset是请求评论开始的序号,limit为请求的条数
再看返回的json结果:
data.comments中是评论的具体内容paging中通过hasMore来告诉我们是否还有更多(判断是否继续抓取)
我们再尝试下将offset设置为0,也加上ts参数:
1 | http://m.maoyan.com/review/v2/comments.json?movieId=248906&userId=-1&offset=0&limit=15&ts=1549965527295&type=3 |
发现也是可以获取数据的:
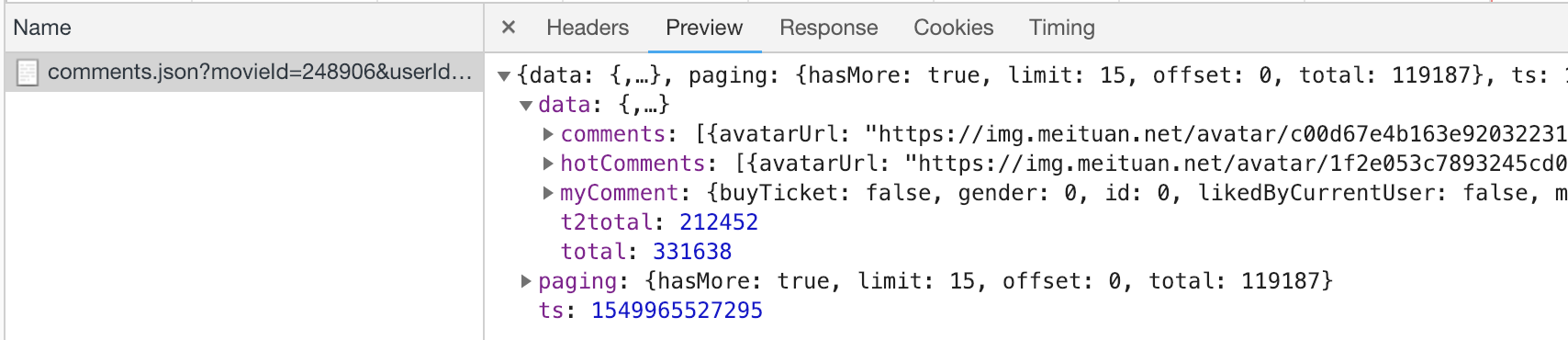
那么通过offset和limit来控制每次请求获取的数量。
我们还可以通过加大limit参数来尝试,是否可以一次性获取更多的评论:
1 | http://m.maoyan.com/review/v2/comments.json?movieId=248906&userId=-1&offset=0&limit=30&ts=1549965527295&type=3 |
效果如下:
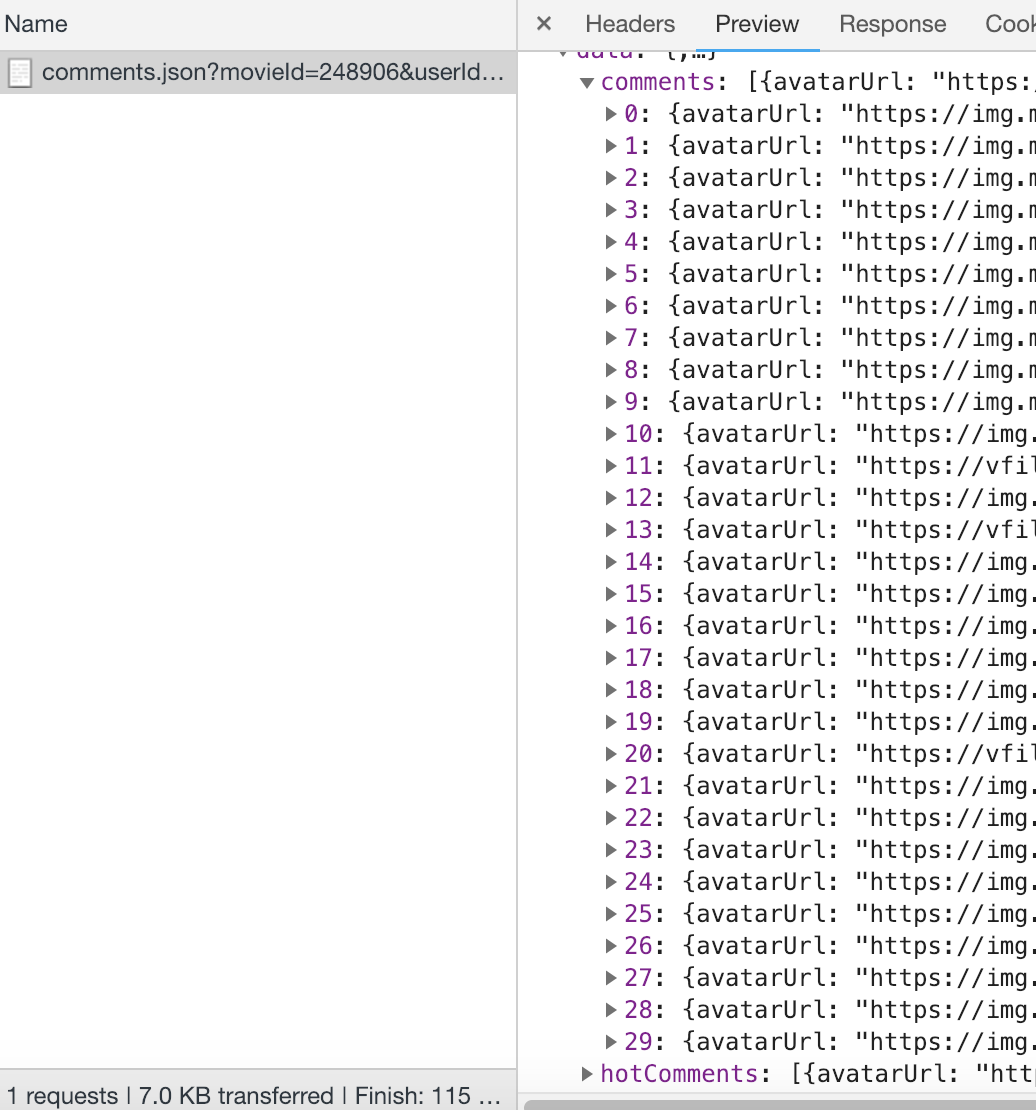
再增加limit的值,会发现评论数回到了15条,可见猫眼系统仅支持每次最多获取30条。
构造请求url 方法一
根据上面的分析,我们构造请求的url就很明确了:
- 从
offset=0&limit=30开始 - 通过返回的
paging.hasMore来判断是否继续抓取 - 下一个抓取的
url中offset+=limit
只能抓取1000条?!
根据上述分析,在返回的json数据中是可以看到总评论数的,但是实际抓取的时候,在offset超过1000之后,返回的数据中hasMore就变成了false。
于是尝试通过浏览器一直下拉刷新,到达offset超过1000的情况,发现页面会不停的发送请求,但也无法获取数据。
那应该就是网站做了控制,不允许offset超过1000。
构造请求URL 方法二
那么就要考虑其他构造url的方法来抓取了。先观察下每个请求返回的信息:
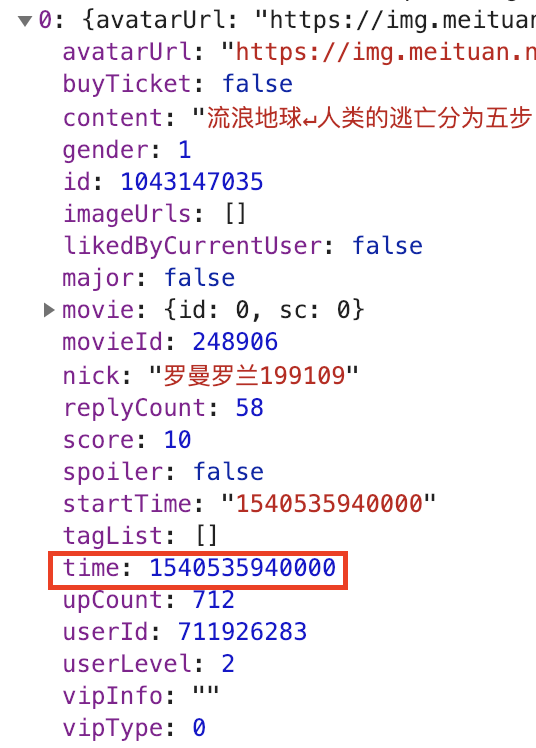
发现每个comment里都包含有一个time信息,把time做一下处理:
1 | 2019-02-13 13:38:00##感觉韩朵朵这个人设是多余的 |
可以发现后台是按照时间顺序的,每分钟一个间隔,那么就可以考虑根据每次返回comment中的时间来更新url中的ts即可。
由于不确定每次请求返回的数据中包含了多长的时间段,且返回的第一个评论时间戳与第二个评论是不同的,所以抓取思路如下:
- 获取请求数据
- 记录第一个时间戳
- 记录第二个时间戳
- 当遇到第三个时间戳时,将
ts设置为第二个时间戳,重新构造url - 如果单次抓取中每遇到第三个时间戳,则通过修改
offset来继续抓取,直到遇到第三个时间戳
实现
根据上面思路,实现相对就比较简单了:
生成url
1
2
3
4
5def get_url():
global offset
url = 'http://m.maoyan.com/review/v2/comments.json?movieId=' + movieId + '&userId=-1&offset=' + str(
offset) + '&limit=' + str(limit) + '&ts=' + str(ts) + '&type=3'
return url访问url
1
2
3
4
5
6
7
8
9
10
11
12def open_url(url):
global ua
try:
headers = {'User-Agent': ua.random}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except Exception as e:
print(e)
return None数据处理:将评论保存并判断是否要继续抓取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29def parse_json(data):
global count
global offset
global limit
global ts
ts_duration = ts
res = json.loads(data)
comments = res['data']['comments']
for comment in comments:
comment_time = comment['time']
if ts == 0:
ts = comment_time
ts_duration = comment_time
if comment_time != ts and ts == ts_duration:
ts_duration = comment_time
if comment_time !=ts_duration:
ts = ts_duration
offset = 0
return get_url()
else:
content = comment['content'].strip().replace('\n', '。')
print('get comment ' + str(count))
count += 1
write_txt(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment_time/1000)) + '##' + content + '\n')
if res['paging']['hasMore']:
offset += limit
return get_url()
else:
return None
最后一共抓取评论131106条,足够做各种分析了,完整代码可见GitHub:https://github.com/keejo125/web_scraping_and_data_analysis/tree/master/maoyan
1 | 2019-02-13 18:13:10,962 - get_comments.py[line:78] - INFO: get comment 131098 |
如果有更好的方法,欢迎一起探讨。
