背景
知乎是一个比较出名也很有趣的网站,里面很多问题和回答也很有意思。之前看了一些爬虫相关文章经常会以抓取知乎来做一些分析。本次也尝试使用python抓取知乎某问题的全部答案。
思路
使用爬虫抓取数据其实主要还是要先弄清楚网页展示的方式,现在大部分网页是基于模板动态生成,具体数据通过json等方式传递,这样的话,其实我们只需要直接通过请求抓取json部分即可,而不需要通过获取整个html然后在分析抓取需要部分。
- 先随便打开一个知乎首页的问题,比如:
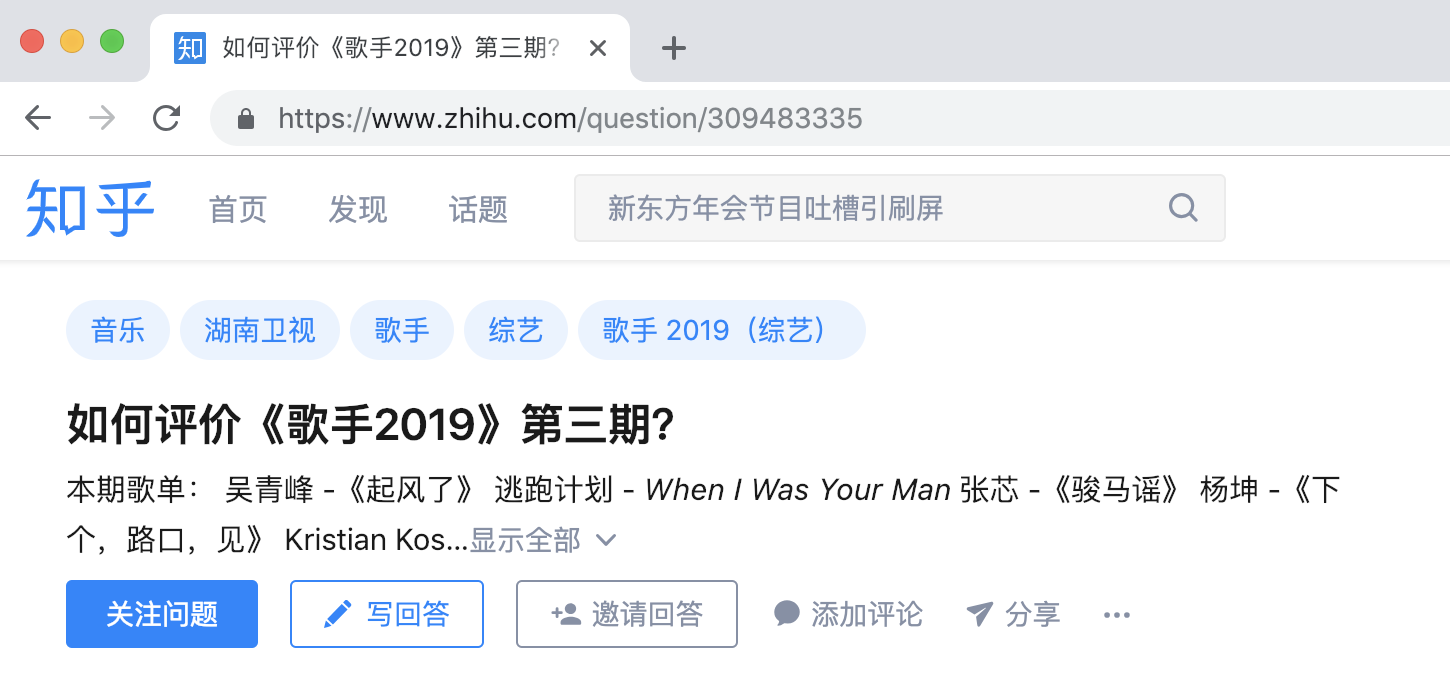
通过在chrome里F12查看网络加载可以发现,有一个
answer?相关的请求,在右边的Preview里看下返回的数据,果然答案就在里面。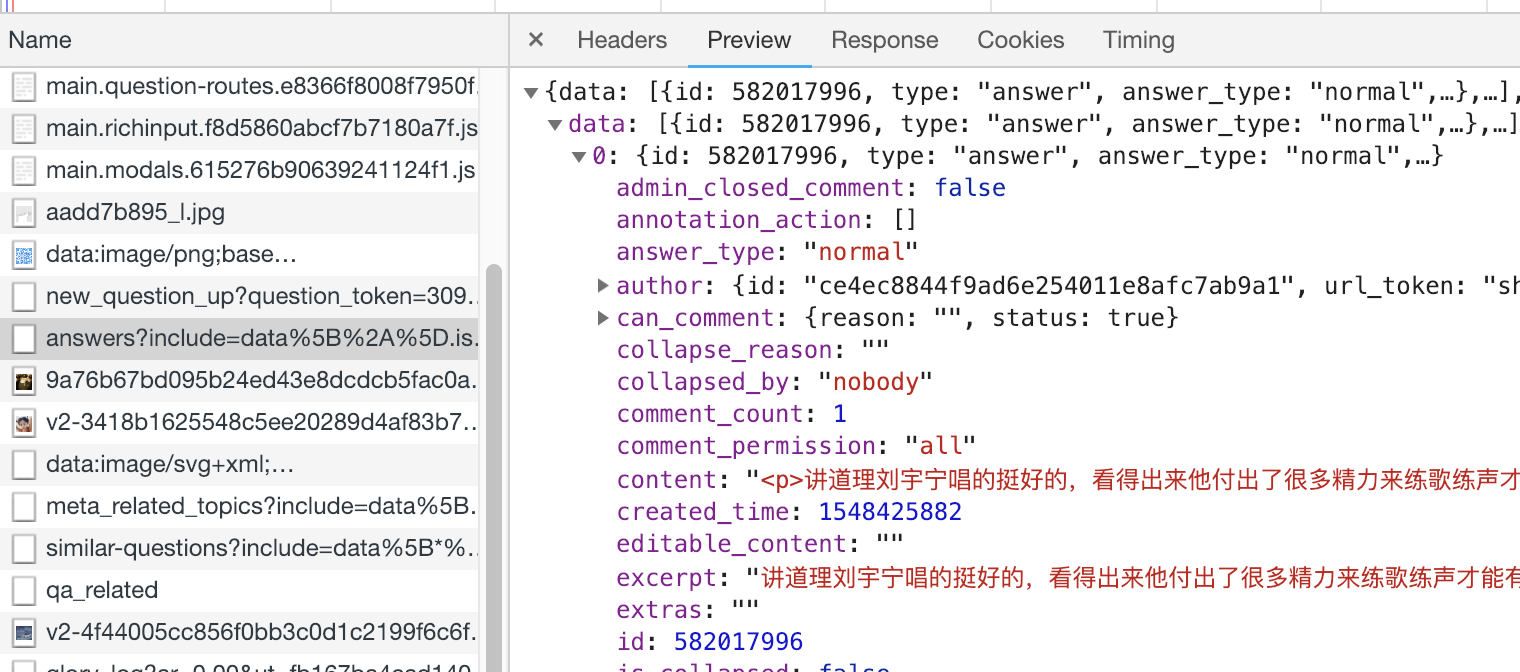
再看仔细分析下返回的这个
json结构: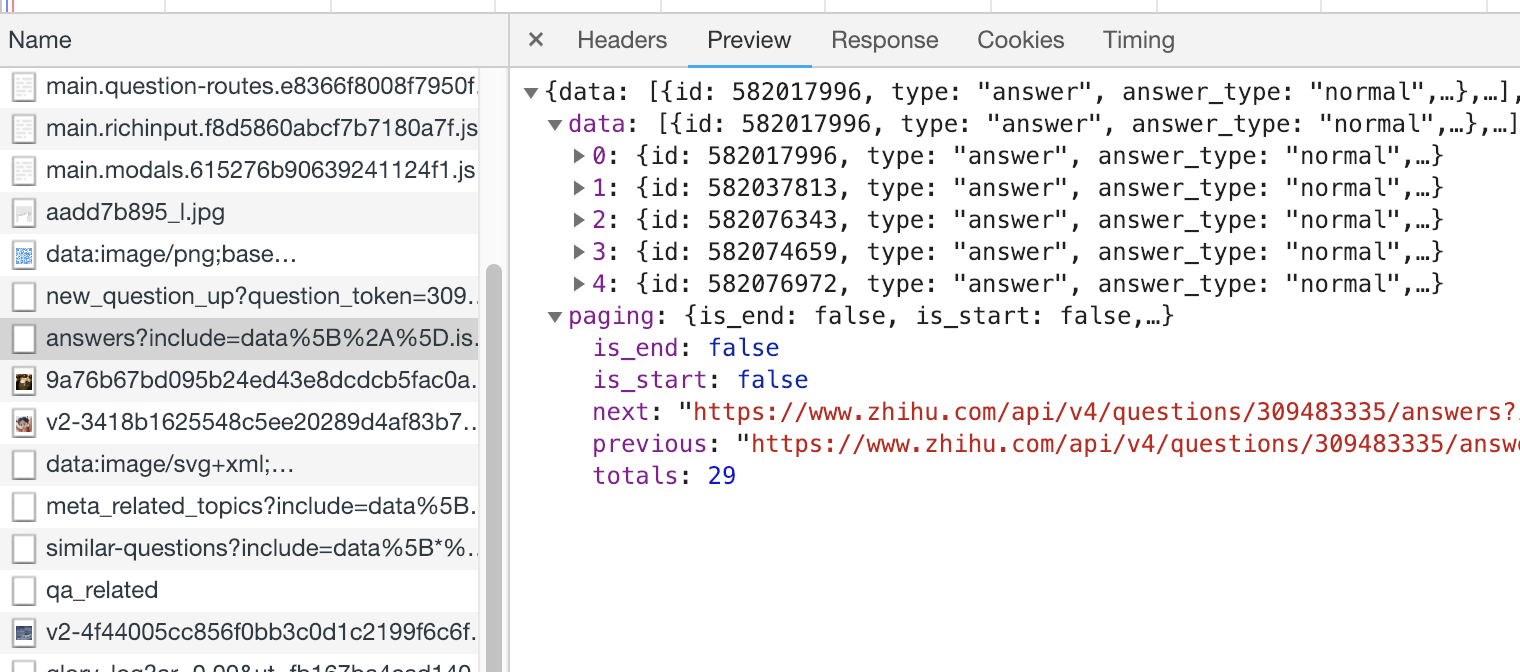
- 每个
json数据中data字段都含有多个答案体 - 每个答案体里,具体内容存在于
content字段,而该字段是一段html,需要使用BeautifulSoup来解析。 - 每个
json数据中paging字段包含了返回的数据是否是这个问题的起止答案,并且给除了上一批答案的请求地址以及下一批答案的请求地址,和总答案数。
- 每个
于是可以通过随便获取一个请求地址,然后在
data字段中获取答案,并根据paging字段来迭代获取其他的答案。
具体实现
根据上述的思路,那么实现起来就比较简单了
- 先获取手动获取感兴趣的问题的网址
- 在chrome的F12中找到对应的答案请求地址(开头为
https://www.zhihu.com/api/v4/questions/) - 通过发起请求获取返回的
json数据 - 在返回的
json数据中,遍历data字段,并使用·BeautifulSoup来解析出答案 - 在返回的
json数据中,读取paging字段,获取上一个请求地址或者下一个请求地址 - 迭代请求,直到结束
具体的实现,可以参考我的github,https://github.com/keejo125/。
