该系列为南京大学课程《用Python玩转数据》学习笔记,主要以思维导图的记录
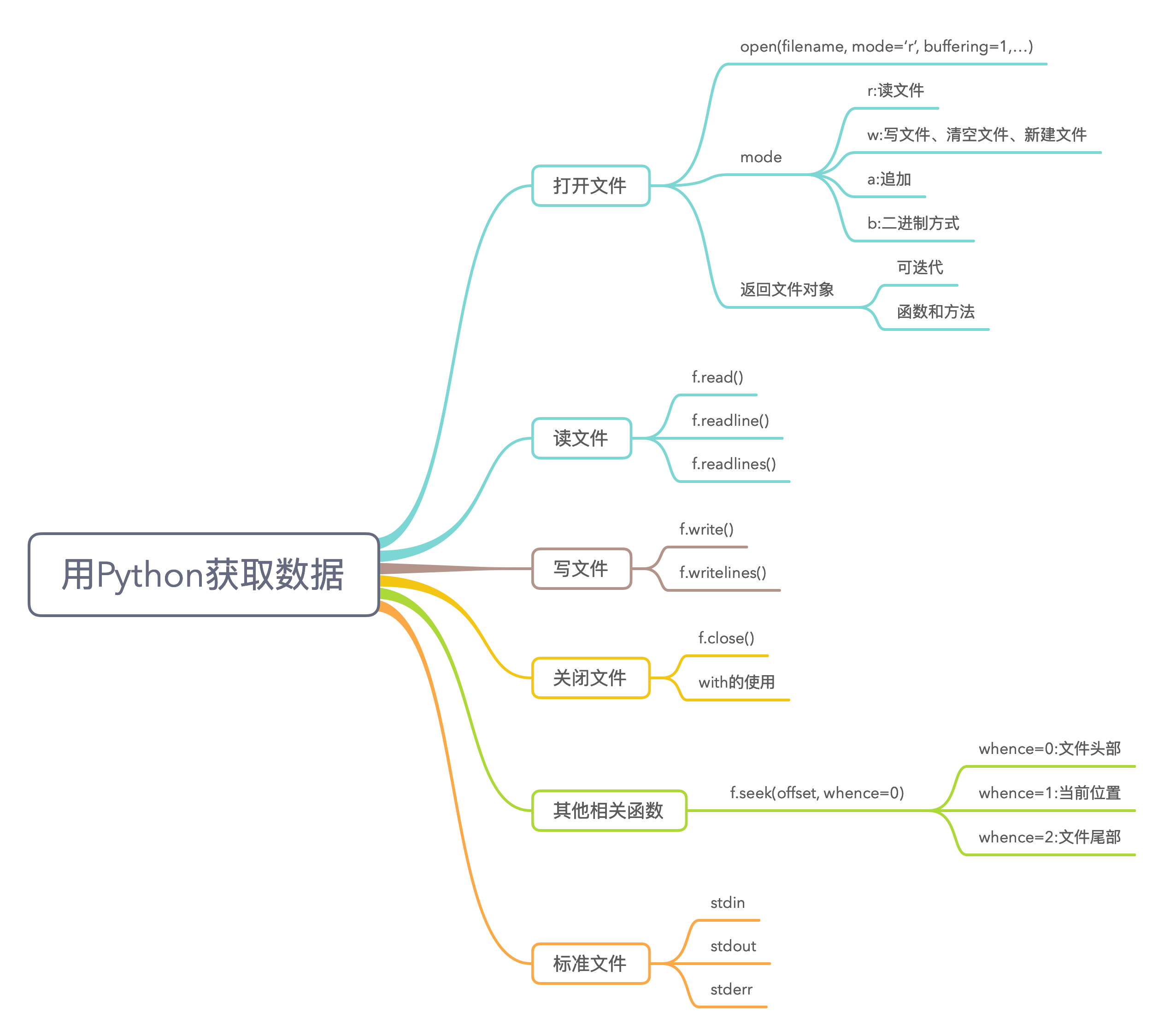
3.1 本地数据获取
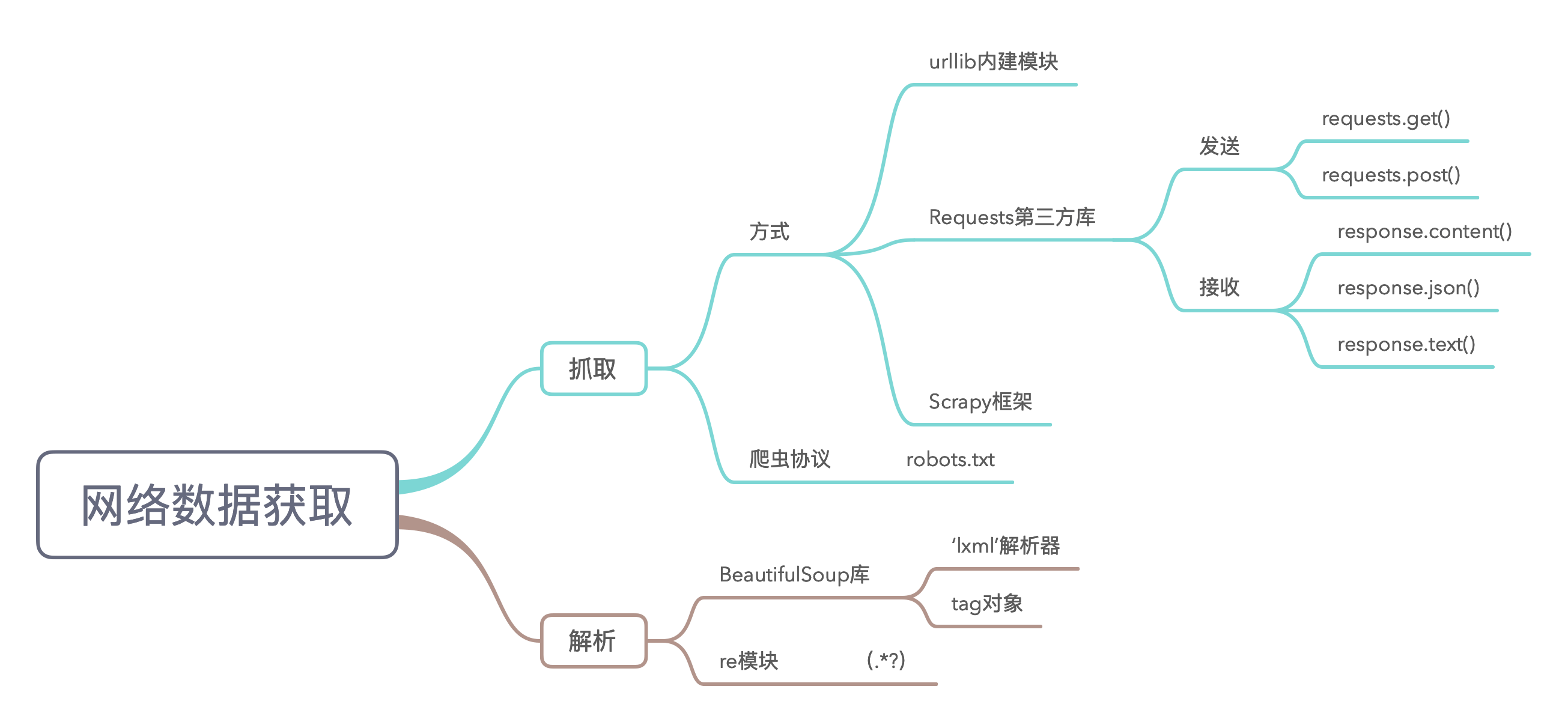
3.2 网络数据获取
爬虫小实验
请在豆瓣任意找一本图书,抓取它某一页的短评并进行页面解析将短评文字抽取后输出,
再对其中的评分进行抽取计算其总分。
1 | import requests |
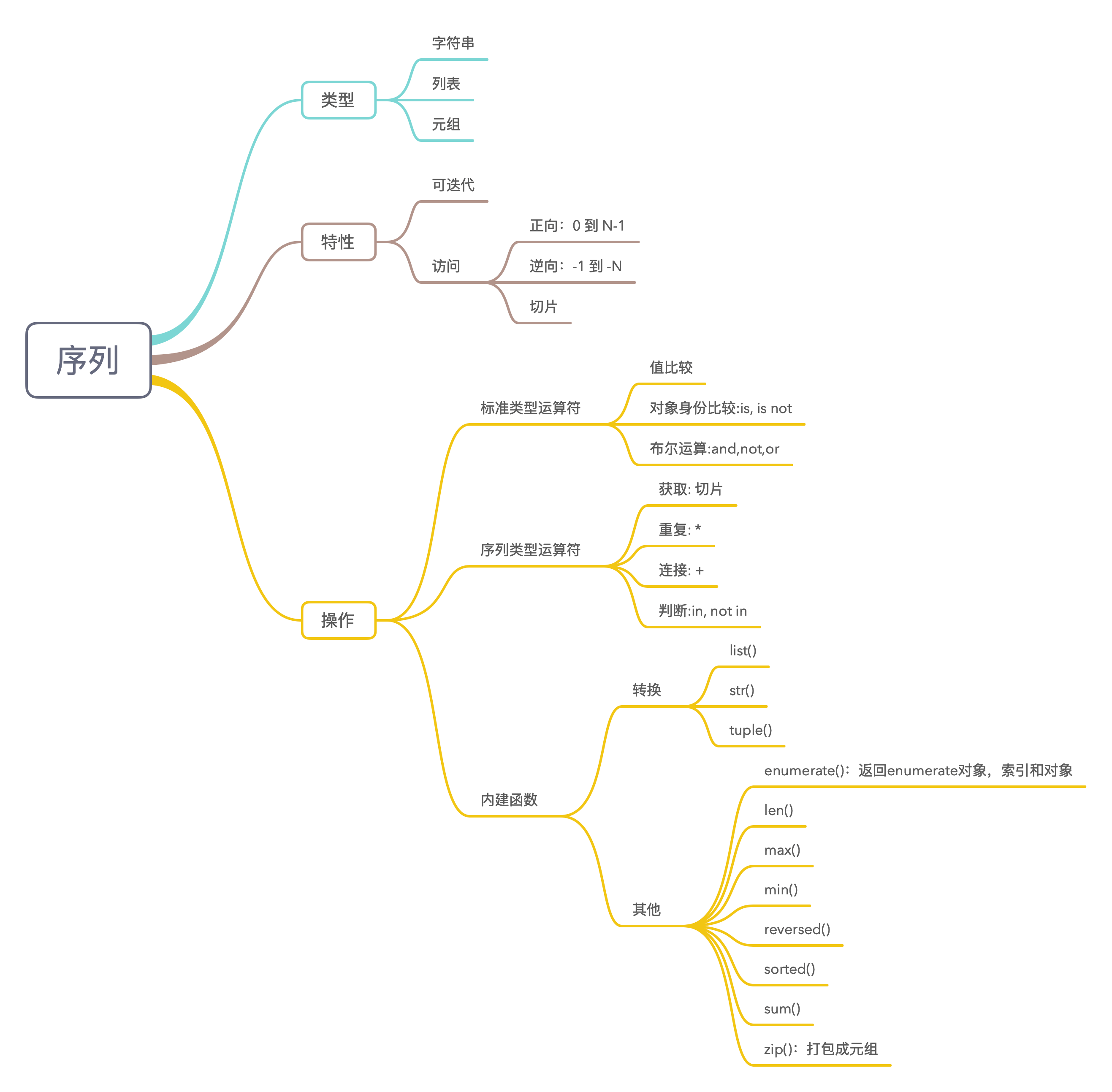
3.3 序列
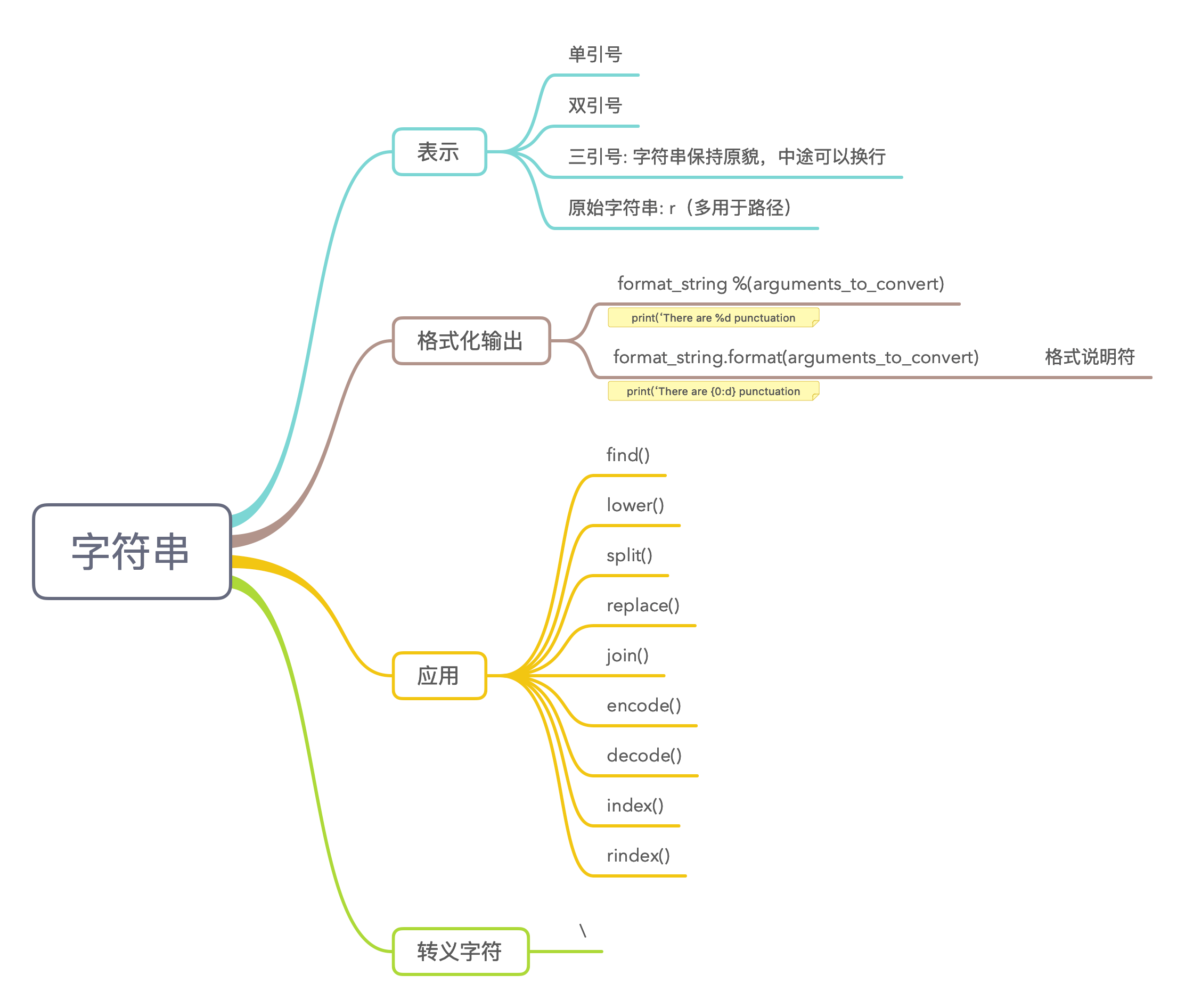
3.4 字符串
编程练习题
使用以下语句存储一个字符串:
string = ‘My moral standing is: 0.98765’
将其中的数字字符串转换成浮点数并输出。
(提示:可以使用find()方法和字符串切片或split()方法,提取出字符串中冒号后面的部分,然后使用float函数,将提取出来的字符串转换为浮点数)1
2
3
4if __name__ == '__main__':
string = 'My moral standing is: 0.98765'
out = string.split(' ')[-1]
print(float(out))自定义函数move_substr(s, flag, n),将传入的字符串s按照flag(1代表循环左移,2代表循环右移)的要求左移或右移n位(例如对于字符串abcde12345,循环左移两位后的结果为cde12345ab,循环右移两位后的结果为45abcde123),结果返回移动后的字符串,若n超过字符串长度则结果返回-1。main模块中从键盘输入字符串、左移和右移标记以及移动的位数,调用move_substr()函数若移动位数合理则将移动后的字符串输出,否则输出“the n is too large”。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def move_substr(s, flag, n):
if n <= len(s):
if flag == 1:
s = s[n:] + s[:n]
elif flag == 2:
s = s[-n:] + s[:-n]
return s
else:
return 'the n is too large'
if __name__ == '__main__':
s = input('Please input s:')
flag = eval(input('Please input flag:'))
n = eval(input('Please input n:'))
print(move_substr(s, flag, n))
讨论
有一天一个江湖传说中的奥数高手冷冷地问我:你知道2000个5(55555…55555)除以84的余数是多少吗?给你5分钟时间。我打开Python IDLE,5秒钟告诉了他答案,看到屏幕上只有一行代码,他的脸在风中抽搐着。如果你遇到他,你几秒可以KO他?快来亮出你的KO秘籍吧。
1 | print(eval('5'*2000) % 84) |
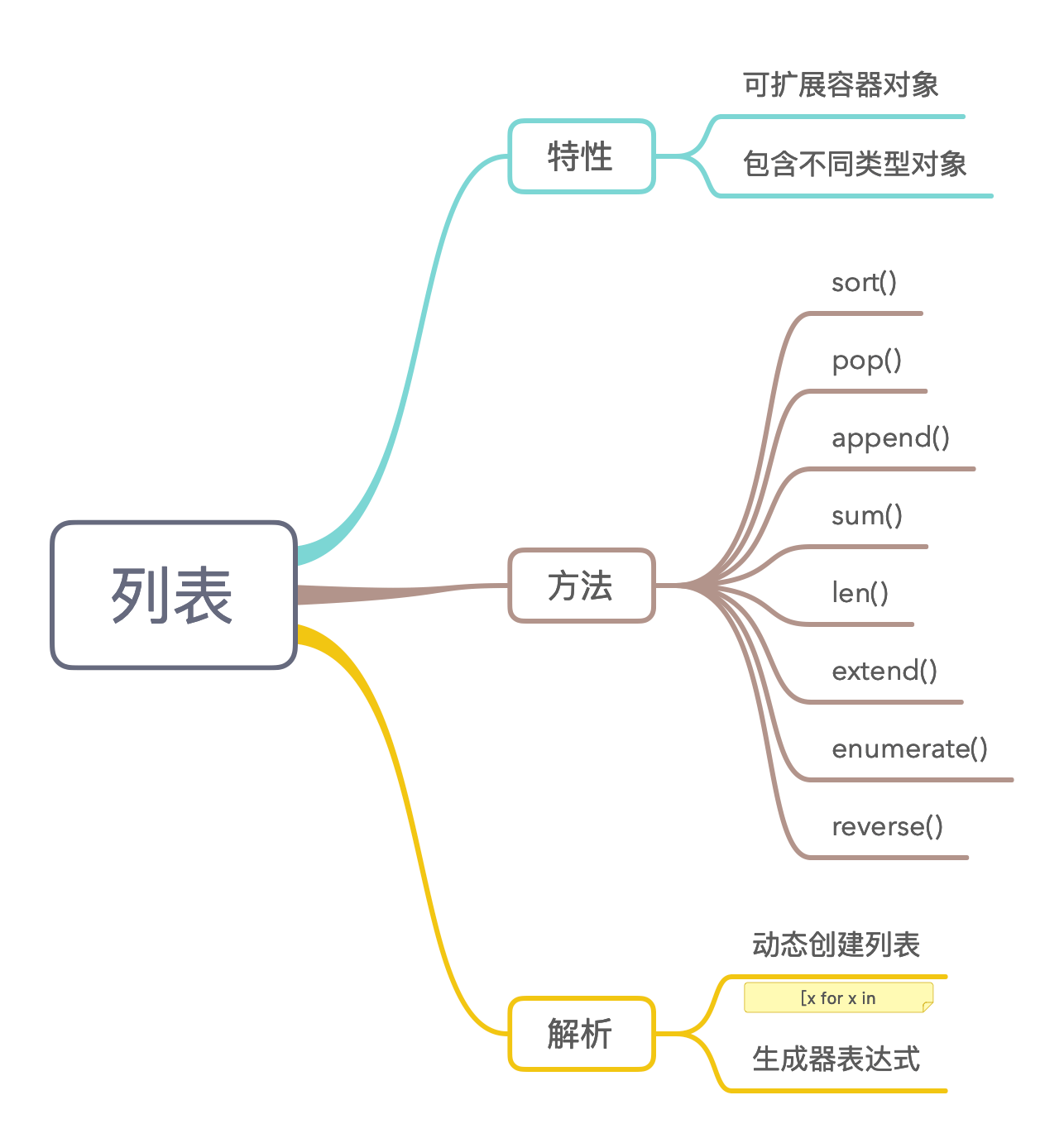
3.5 列表
讨论
假设要生成如下的列表x(1-100之间):
[5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100]
请写出你会用的列表解析表达式。
1 | [x for x in range(5, 101, 5)] |
文件处理实例
创建一个文件 Blowing in the wind.txt,其内容是:
How many roads must a man walk down
Before they call him a man
How many seas must a white dove sail
Before she sleeps in the sand
How many times must the cannon balls fly
Before they’re forever banned
The answer my friend is blowing in the wind
The answer is blowing in the wind
(2) 在文件头部插入歌名“Blowin’ in the wind”
(3) 在歌名后插入歌手名“Bob Dylan”
(4) 在文件末尾加上字符串“1962 by Warner Bros. Inc.”
(5) 在屏幕上打印文件内容
1 | if __name__ == '__main__': |
编程练习题
有一个咖啡列表[‘32Latte’, ‘_Americano30’, ‘/34Cappuccino’, ‘Mocha35’],列表中每一个元素都是由咖啡名称、价格和一些其他非字母字符组成,编写一个函数clean_list()处理此咖啡列表,处理后列表中只含咖啡名称,并将此列表返回。初始化咖啡列表,调用clean_list()函数获得处理后的咖啡列表,并利用zip()函数给咖啡名称进行编号后输出,输出形式如下:
1 Latte
2 Americano
3 Cappuccino
4 Mocha
1 | import re |
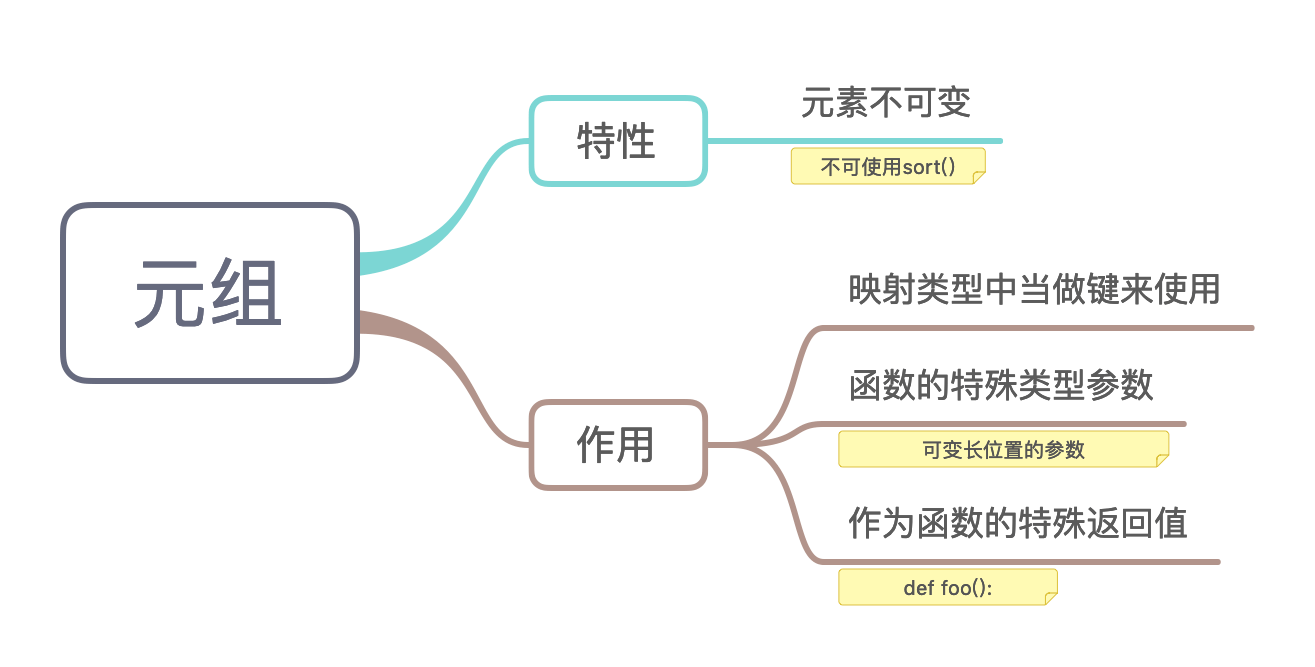
3.6 元组