背景
前面通过爬虫获取了猫眼上”流浪地球“的评论:获取猫眼电影的评论,除了做词云之外,还可以对数据进行分析,看看大家对电影的反响如何。
思路
前面我们再抓取时,将评论的时间和内容通过csv的格式保存下来,并使用;分割。读取csv文件并统计处理就要用到大名鼎鼎的pandas了。
读取数据
pandas提供read_csv方法来直接独处数据保存为DateFrame格式。
1 | df = pd.read_csv('comment.csv', sep=';', header=None) |
数据处理
设置数据列名
由于我们知道数据有两列,先通过这只列名可以方便后续引用。
1
df.columns = ['date', 'comment']
时间日期处理
在
date列,我们保存的数据格式是string,需要把转换为日期格式才能进一步处理。1
df['date'] = pd.to_datetime(df['date'])
我们需要按时间来统计,所以把
date列设置为index:1
df = df.set_index('date')
统计处理
日期筛选
由于我们知道《流浪地球》是2月5日上映的,我们可以对日期进行限定,以免出现有些在上映前的评论,会占用大段的空白情况。
设置
index之后,可以参考list类型操作,由于时间是倒序的,所以可以直接使用[:'2019-02-04']来选取2月4日之后到今天的所有数据。pandas在数据筛选方面相当智能,按照datetime的格式直接筛选即可。1
cacu_df = df[:'2019-02-04']
按日期进行数量统计
pandas中,通过resample方法进行重新采样,通过传入rule参数就可以按需要的频率获取数据,获得一个resampler对象。1
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start', kind=None, loffset=None, limit=None, base=0, on=None, level=None)
resampler对象提供了很多的统计方法,比如汇总求和可使用Resampler.count()。1
2# 按日统计数量
cacu = cacu_df.resample('D').count()这样就完成了按日期求和统计操作。
绘图
画图需要使用matplotlib库,通过导入该库,可直接对DateFrame对象进行画图处理。画图及图表格式化如下:
1 | # 设置中文字体 |
结论
以上就是使用抓取的评论生成日期统计图片的大致思路,完成的实现代码请见:https://github.com/keejo125/web_scraping_and_data_analysis/tree/master/maoyan
结果如下:
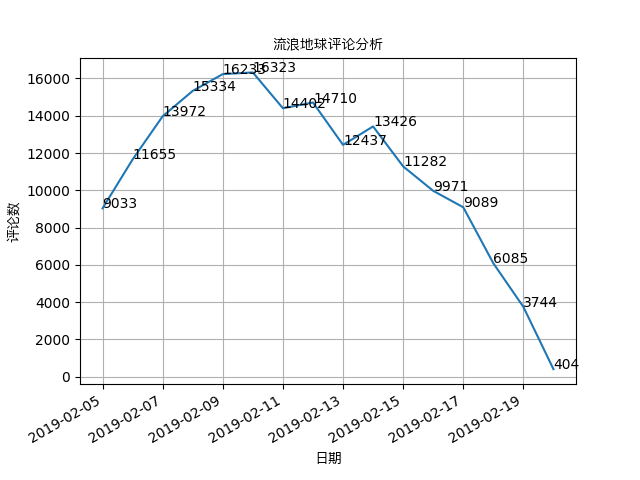
可见从上映之后,关注度直线飙升,到2月10日之后(上映5天),大家关注度逐渐下降。其中2月14日为情人节,大家的关注又有了小幅的上升。也许很多人在这天通过看《流浪地球》过节吧。
拓展
matplotlib画图说明该库是默认不支持中文的,所以如果不经过配置直接画图,设置中文图标会显示为空白方框。详细配置参考上文。
pandas使用更多的
resampler的方法,可见:http://pandas.pydata.org/pandas-docs/stable/reference/resampling.html更多
resample的rule参考下表:
| Date Offset | Frequency String | Description |
|---|---|---|
DateOffset |
None | Generic offset class, defaults to 1 calendar day |
BDay or BusinessDay |
'B' |
business day (weekday) |
CDay or CustomBusinessDay |
'C' |
custom business day |
Week |
'W' |
one week, optionally anchored on a day of the week |
WeekOfMonth |
'WOM' |
the x-th day of the y-th week of each month |
LastWeekOfMonth |
'LWOM' |
the x-th day of the last week of each month |
MonthEnd |
'M' |
calendar month end |
MonthBegin |
'MS' |
calendar month begin |
BMonthEnd or BusinessMonthEnd |
'BM' |
business month end |
BMonthBegin or BusinessMonthBegin |
'BMS' |
business month begin |
CBMonthEnd or CustomBusinessMonthEnd |
'CBM' |
custom business month end |
CBMonthBegin or CustomBusinessMonthBegin |
'CBMS' |
custom business month begin |
SemiMonthEnd |
'SM' |
15th (or other day_of_month) and calendar month end |
SemiMonthBegin |
'SMS' |
15th (or other day_of_month) and calendar month begin |
QuarterEnd |
'Q' |
calendar quarter end |
QuarterBegin |
'QS' |
calendar quarter begin |
BQuarterEnd |
'BQ |
business quarter end |
BQuarterBegin |
'BQS' |
business quarter begin |
FY5253Quarter |
'REQ' |
retail (aka 52-53 week) quarter |
YearEnd |
'A' |
calendar year end |
YearBegin |
'AS' or 'BYS' |
calendar year begin |
BYearEnd |
'BA' |
business year end |
BYearBegin |
'BAS' |
business year begin |
FY5253 |
'RE' |
retail (aka 52-53 week) year |
Easter |
None | Easter holiday |
BusinessHour |
'BH' |
business hour |
CustomBusinessHour |
'CBH' |
custom business hour |
Day |
'D' |
one absolute day |
Hour |
'H' |
one hour |
Minute |
'T' or 'min' |
one minute |
Second |
'S' |
one second |
Milli |
'L' or 'ms' |
one millisecond |
Micro |
'U' or 'us' |
one microsecond |
Nano |
'N' |
one nanosecond |
