背景
前面通过爬虫获取了猫眼上”流浪地球“的评论:获取猫眼电影的评论,并制作了词云,使用pandas初步分析了电影热度情况,还可以分析什么呢?
SnowNLP是个开源的NPL分析库,可以方便的进行中文分词,特点是可以进行情感评测,来分析评论的积极程度,主要用于电商网站中的商品评论的分析。那么分析下电影评论情况如何呢?
思路
前面我们再抓取时,将评论的时间和内容通过csv的格式保存下来,并使用;分割。
读取数据
pandas提供read_csv方法来直接独处数据保存为DateFrame格式。
1 | df = pd.read_csv('comment.csv', sep=';', header=None) |
获取情感评分
通过pandas读取csv后,评论会保存在df[1]中,我们需要对每一条评论进行情感评分,pandas提供了apply功能配合lambda就可以方便的实现了:
1 | sentiment = lambda x:SnowNLP(x).sentiments |
数据处理
设置数据列名
1
df.columns = ['date', 'comment', 'sentiment']
时间日期处理
在
date列,我们保存的数据格式是string,需要把转换为日期格式才能进一步处理。1
df['date'] = pd.to_datetime(df['date'])
我们需要按时间来统计,所以把
date列设置为index:1
df = df.set_index('date')
统计处理
日期筛选
由于我们知道《流浪地球》是2月5日上映的,我们可以对日期进行限定,以免出现有些在上映前的评论,会占用大段的空白情况。
设置
index之后,可以参考list类型操作,由于时间是倒序的,所以可以直接使用[:'2019-02-04']来选取2月4日之后到今天的所有数据,并选取sentiment列。1
cacu_df = df[:'2019-02-04']['sentiment']
按日期进行数量统计
pandas中,通过resample方法进行重新按日采样,并求汇总的平均值。1
cacu = cacu_df.resample('D').mean()
这样就完成了按日期求和统计操作。
绘图
画图需要使用matplotlib库,通过导入该库,可直接对DateFrame对象进行画图处理。画图及图表格式化如下:
1 | # 通过设置中文字体方式解决中文展示问题 |
结论
以上就是使用抓取的评论生成情感分析统计图片的大致思路,完成的实现代码请见:https://github.com/keejo125/web_scraping_and_data_analysis/tree/master/maoyan
结果如下:
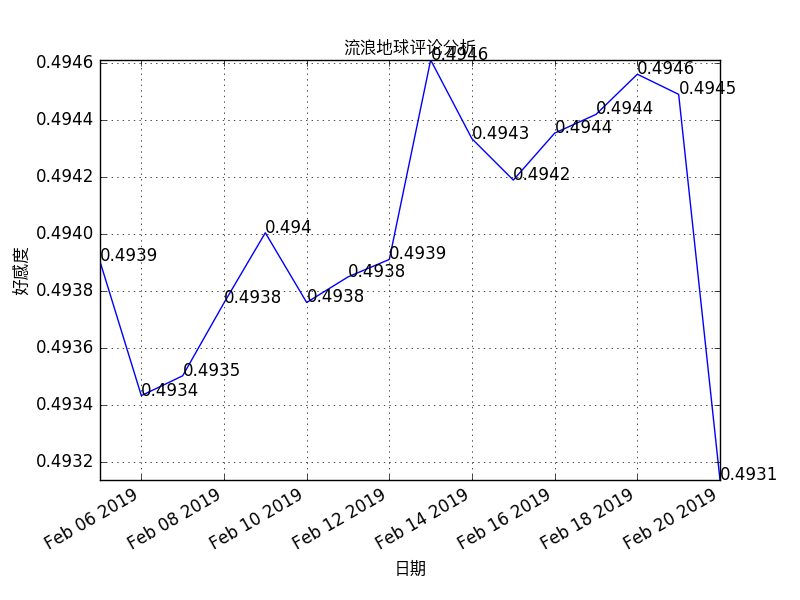
根据SnowNLP,sentiment值是指:positive的概率,可以简单理解为分值大于0.5为积极,小于为消极。那么这个结论就很奇怪了,那么我们看下每个评论的评分情况:
1 | 0 中国科幻电影,继续加油↖(^ω^)↗ 0.5 |
这个评分。。。相当不准。。。
再看下官网的说明:
情感分析(现在训练数据主要是买卖东西时的评价,所以对其他的一些可能效果不是很好,待解决)
好吧,希望以后可以尽快解决啦
