背景
前段时间有人在群里分享了爬虫咪蒙公众号的所有文章,可以通过深度学习进行各种分析,但由于咪蒙账号已封,所以链接点进去也看不到了。个人还是比较喜欢看新世相的公众号的,看看怎么把它的文章也都爬下来。
思路
从哪里爬?
爬虫一般得用浏览器访问,然后找到相关的请求接口,通过修改参数来伪造请求获取数据。微信公众号文章浏览器上哪里看呢?搜了下,有三种方式:
搜狗的微信搜索:http://weixin.sogou.com
该方式只能搜到公众号最新10篇文章,放弃
使用fiddler抓包,并用手机模拟器模拟手机访问
难度比较大,放弃
在微信公众平台:https://mp.weixin.qq.com/
通过插入文章的方式可以查找公众号的所有文章,相对简单,pick
爬取过程
由于微信公众平台登陆需要手机扫描二维码,不可避免的要“人机耦合”了,所以打算全程采取使用selenium来做:
新建ChromeDriver并登陆网页,sleep10秒钟用于手工扫码登陆
1
2
3
4
5
6
7
8
9
10
11
12
13url = "https://mp.weixin.qq.com/"
option = webdriver.ChromeOptions()
# option.add_argument('headless')
driver = webdriver.Chrome(executable_path='./chromedriver', options=option)
driver.implicitly_wait(60)
driver.get(url)
driver.find_element_by_name('account').clear()
driver.find_element_by_name('password').clear()
driver.find_element_by_name('account').send_keys(config.account)
driver.find_element_by_name('password').send_keys(config.password)
driver.find_element_by_class_name('btn_login').click()
# 手动扫码
time.sleep(10)
登陆后打开素材管理,并新建图文素材:
1
2
3
4# 打开素材管理
driver.find_element_by_link_text('素材管理').click()
# 点击新建图文素材
driver.find_element_by_class_name('weui-desktop-btn_primary').click()
需要注意的是,这里会新建一个窗口,在selenium中页面切换操作,需要获取windows_handler然后切换:
1
2
3
4# 新建图文素材 会有新建页面
all_handles = driver.window_handles
# 切换到新窗口
driver.switch_to.window(all_handles[1])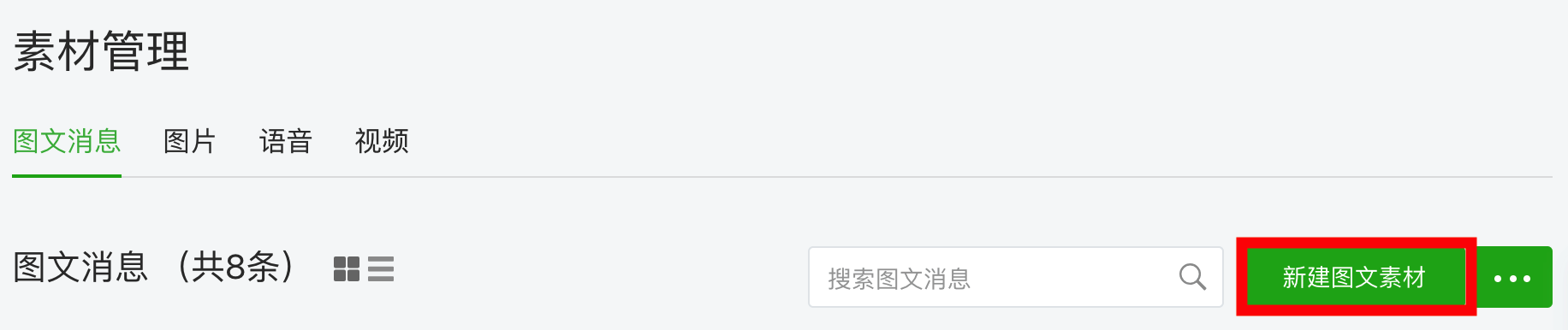
在新建素材页面,点击插入链接的按钮,并选择查找文章,输入“新世相”搜索找到对应的微信号
1
2# 点击插入链接
driver.find_element_by_id('edui24_body').click()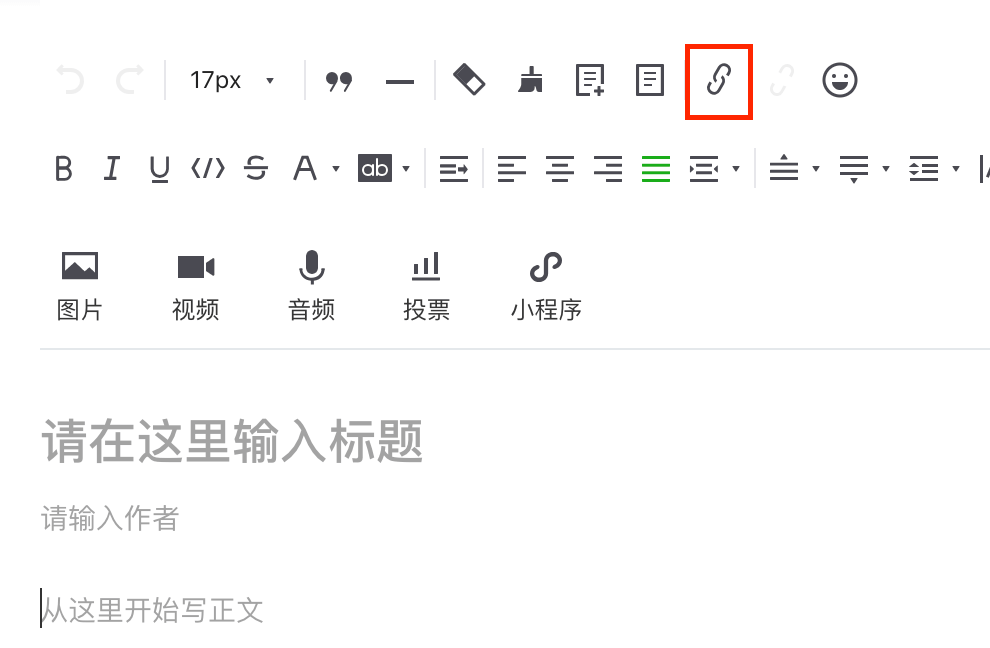
1
2
3
4
5
6
7
8
9
10# 选择查找文章
driver.find_element_by_xpath('//*[@id="myform"]/div[3]/div[1]/div/label[2]/span').click()
# 输入公众号名称
driver.find_element_by_class_name('js_acc_search_input').send_keys('新世相')
# 搜索
driver.find_element_by_class_name('js_acc_search_btn').click()
# 选择新世相
# driver.find_element_by_class_name('search_biz_item').text
# Out[53]: '订阅号\n新世相 微信号:thefair2'
driver.find_element_by_class_name('search_biz_item').click()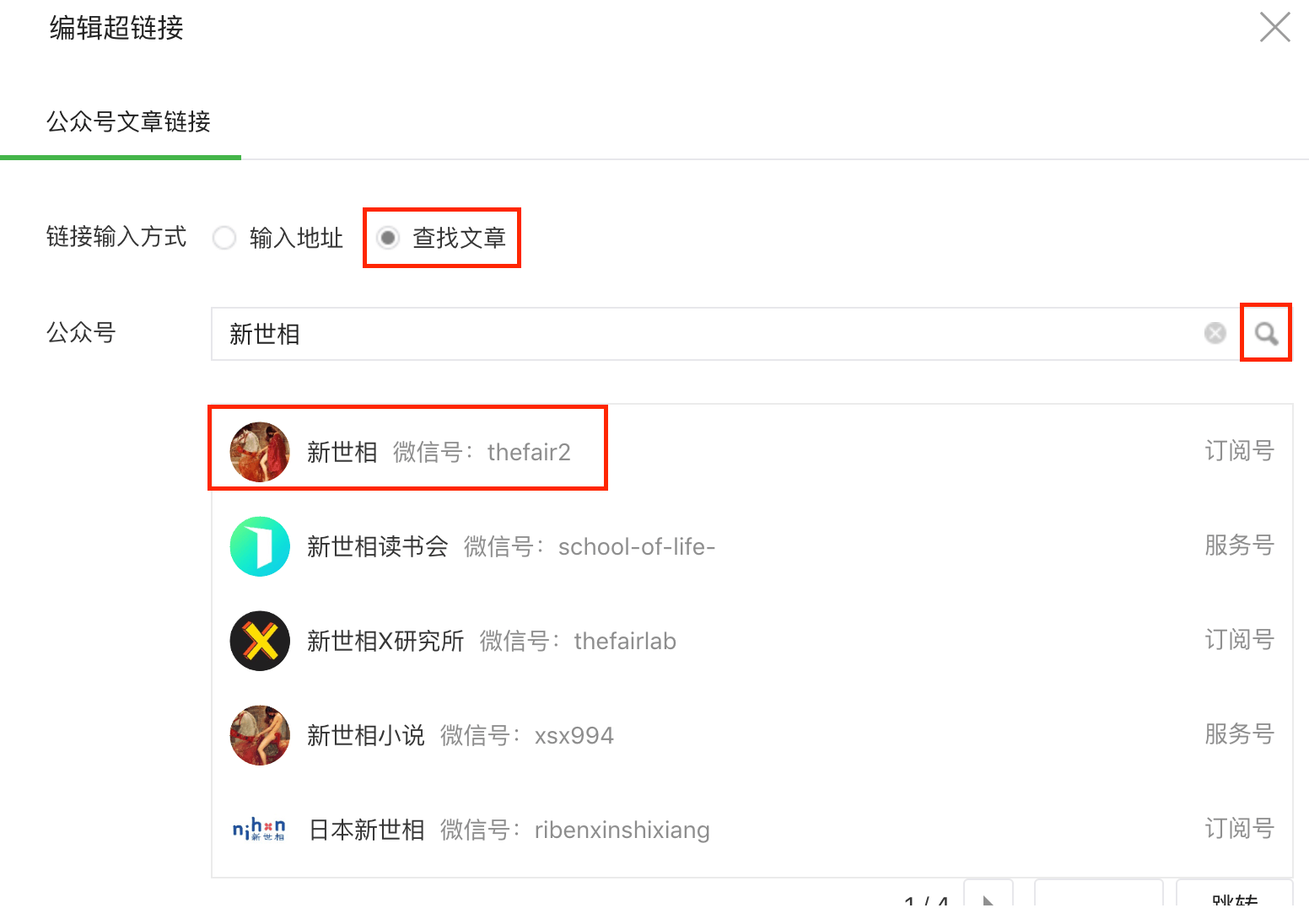
新建一个
csv文件用于保存文章标题与固定链接1
2
3# 新建Csv
f = open('articles.csv', 'w')
writer = csv.writer(f, delimiter=';')找到搜索结果部分,获取文章标题与链接,并通过不停的点击“下一页”,来爬取全部文章
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 选择结果输出部分
search_article_result = driver.find_element_by_class_name('search_article_result')
count = 1
while True:
# 获取列表
temp_list = search_article_result.find_elements_by_class_name('my_link_item')
logging.info("抓取第" + str(count) + "页")
for item in temp_list:
title = item.text.replace('\n', ';')
logging.info(title)
# 文章链接
href = item.find_element_by_tag_name('a').get_attribute('href')
writer.writerow([title, href])
try:
search_article_result.find_element_by_class_name('page_next').click()
count += 1
time.sleep(random.randint(20,40))
except Exception as e:
logging.exception("获取列表失败")
driver.quit()
return这里需要注意,爬取过程要多通过sleep来暂停下,不然很快就会提示“操作过于频繁”而被暂停了
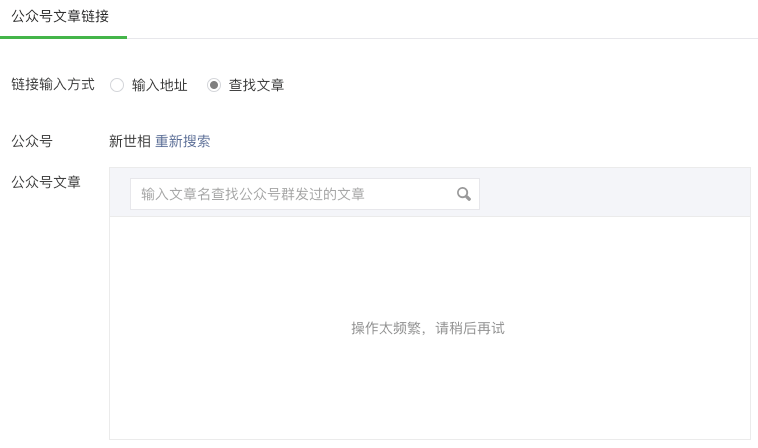
爬取结果
如果中途被反爬了,就在上次爬到的页数那儿开始继续吧,多耦合几次还是可以爬完的
总结
由于公众号管理这块登陆涉及到了扫描二维码,安全性高了很多,大大增加了爬虫的难度。相对来说,腾讯的反爬还是做的非常好的,直接使用selenium来模拟人操作,中间sleep也相当长的时间了,还是会被提示“操作太频繁”而被中断,且中断时间长达好几个小时,那么如果采用请求的方式,那估计会被封的更快吧。。。
完整代码参考:https://github.com/keejo125/web_scraping_and_data_analysis/tree/master/weixin
如果大家有更好的方法,也欢迎分享。
