背景
前期以《流浪地球》为例,介绍了抓取猫眼电影评论和分析的爬虫,参考:获取猫眼电影的评论,通过猫眼的接口获取了全量的电影评论。
最近有人在github上提了两个issue,说无法获取评论信息了。
分析
根据最开始的思路,猫眼获取电影评论的接口url如下:
1 | http://m.maoyan.com/review/v2/comments.json?movieId=248172&userId=-1&offset=45&limit=15&ts=1557915814000&type=3 |
其中主要参数为:
- movieId:电影的id
- offset:获取的起始评论为第几条
- limit:每次获取评论的条数
- ts:获取评论的时间,该数值为以ms为单位的unix时间戳
之前获取的思路是,
- 初始ts为0,及当前时间
- 获取评论之后,将最后一条评论的时间转换为时间戳ts,并构造请求url
- 再次获取以上次ts为当前时间的评论
这样通过不断的将时间往前推,就可以获取所有的评论了。
现在用相同的接口测试我们会发现:
当ts=0时,可以获取当前最新的评论,并返回当前的时间戳。
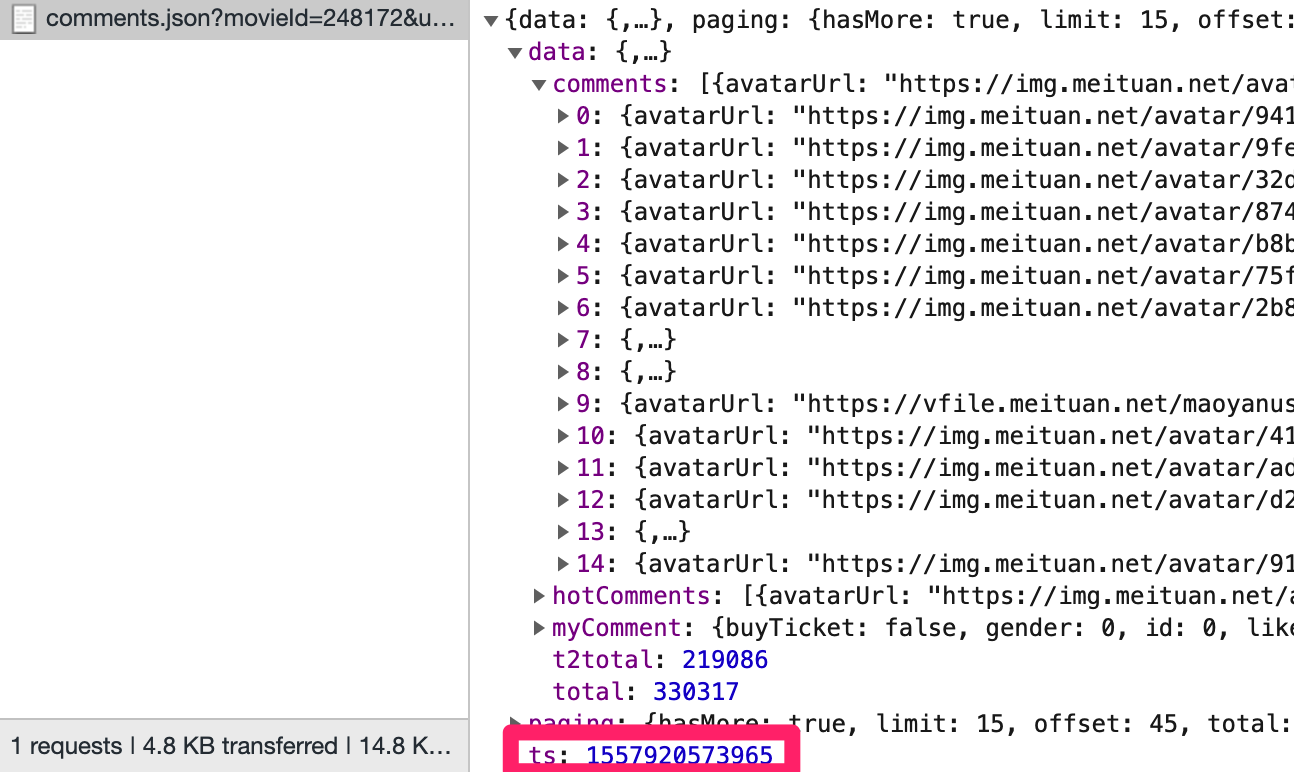
当我们将ts修改为前一天的时间则会返回异常,并且返回的时间即为我们输入的时间。
1
{"data":{"t2total":219089,"total":330321},"paging":{"hasMore":false,"limit":0,"offset":0,"total":0},"ts":1557834316000}

注:1557920573965转为时间为:2019-05-15 19:42:53;
前一天 2019-05-14 19:42:53 转为时间戳:1557834173000
我们将时间修改为当前时间之前1小时(1557916973000)就会发现又可以获取数据了。
前期我们可以将limit指定为30,来每次获取30条数据。当我们将ts设置为0是,limit保持为30,同样的返回异常:
1
{"data":{"t2total":219106,"total":330348},"paging":{"hasMore":false,"limit":0,"offset":0,"total":0},"ts":1557921388556}
我们将limit设置为15时,返回正常。
结论
根据上述分析,基本上可以得出如下结论:
- 我们可以通过猫眼的接口获取电影评论,但无法通过修改ts来获取全量评论。
- 猫眼通过ts来判断是否为人为浏览,当ts与当前时间差距小于一小时时,可以获取数据,而大于一小时则不行。
- 猫眼显示每次最多获取15条评论,超过15则也返回异常。
那么获取评论的思路就变为:
- 通过接口,初始设置ts=0来获取数据
- 使用返回的ts值,以及offset和limit来构成url
- 获取更多的数据
需要注意的是,该接口仅可获取1000条评论,超过1000之后返回hasMore:false,无法继续获取。
具体时间参考:https://github.com/keejo125/web_scraping_and_data_analysis/tree/master/maoyan
issue参考:https://github.com/keejo125/web_scraping_and_data_analysis/issues/1
