背景
《我是唱作人》是爱奇艺自制的原创音乐节目,当前十分火爆,本周更是上半季的最后一集。我们可通过抓取人们观看节目并发表的评论,看看这节目以及最后决赛究竟如何。
评论抓取
我们先访问爱奇艺的官网,找到对应的节目:https://www.iqiyi.com/a_19rrhuo9bd.html
会发现仅有节目观看,但是并没有用户的评论,而我们手机APP应用上却是可以看到很多评论的.
那么我们在chrome中打开开发者界面,勾选手机版,并将网址换成手机版地址:https://m.iqiyi.com/v_19rsh3hwuo.html
接下来就是要找到对应评论的接口地址了。
通过不断的下拉会发现,评论是会自动加载的,打开chrome开发者工具中的Network信息,可以很容易的发现,在下拉过程中会有新的请求产生,且都是以get_comments.action开头的,查看这些请求信息:
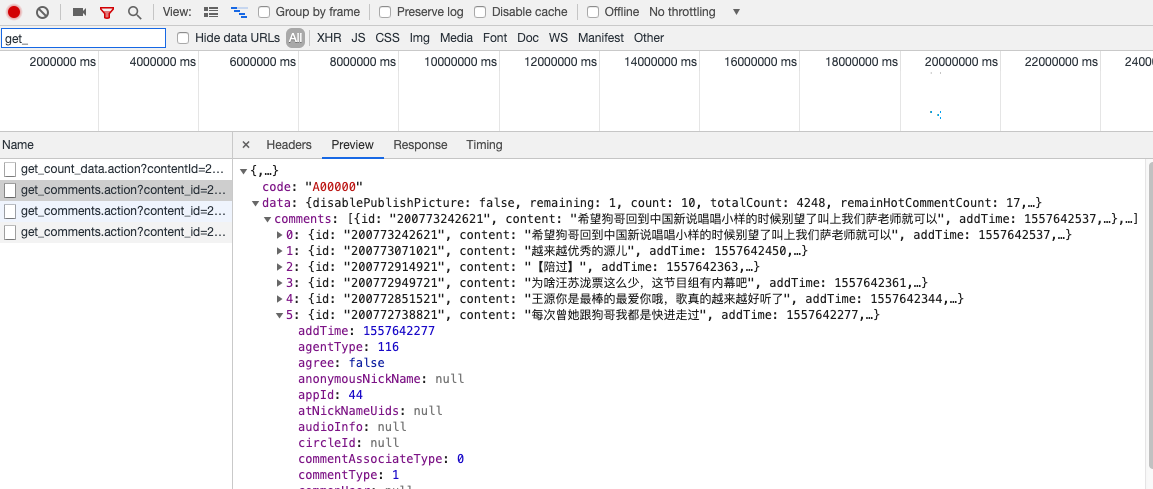
这就是我们需要找的评论接口了。我们比较几个地址,来查找规律:
1 | https://sns-comment.iqiyi.com/v3/comment/get_comments.action?content_id=2400411900&types=hot%2Ctime&business_type=17&agent_type=119&agent_version=9.9.0&authcookie= |
可以发现主要有这么几个参数:
- content_id:对应某个视频
- types:直接访问页面时会自动加载一部分评论这时候types值为hot,在不断下拉加载新的评论是,types的值变为time
- last_id:这个参数在后续下拉加载中会不断变化,是记录目前已加载到哪条评论的参数
- 其他参数:
&business_type=17&agent_type=119&agent_version=9.9.0&authcookie=保持不变
我们再观看第一个请求的具体内容
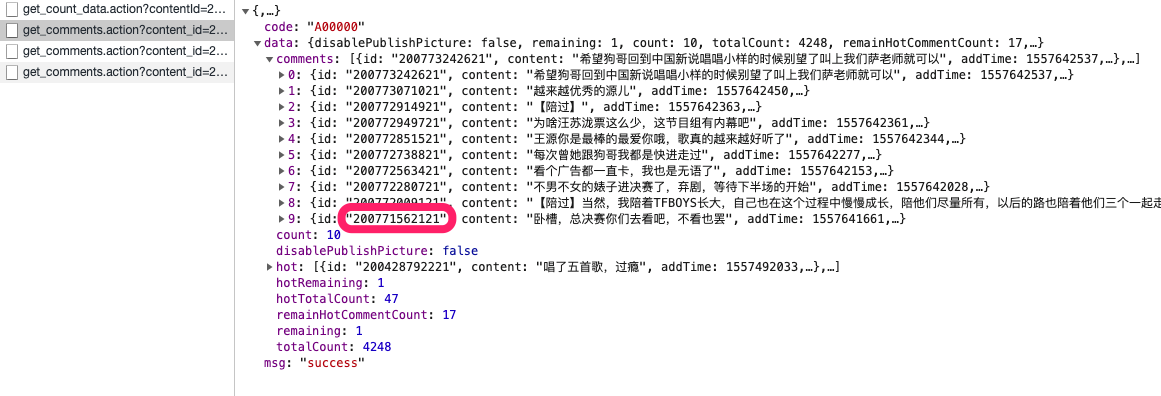
可以发现最后一个评论的id,正好是下一次请求中last_id参数的值。
另外,我们发现有一个remaining的返回值,并且是1,所以我们猜想这个是用于判断是否已加载所有评论。
最后我们看下我们可以获取哪些数据:

根据上图,可以看到,我们可以获取到评论的时间(addTime)、评论的内容(content)、用户信息(userInfo)等,其中用户信息中可以获取用户昵称(uname),性别(gender)等。
我们这次分析观看该节目的用户男女比例和评论内容中的词频分析,那么只要获取评论内容,用户昵称、性别即可。
根据上述思路,整个抓取过程就出来了:
- 先访问节目首页获取初始评论
- 解析返回值并获取数据
- 通过初始评论中的最后一条评论的id构造新的评论获取url
- 通过
remaining返回值进行循环,直至获取所有评论数据
实现:
1 | # -*- coding: utf-8 -*- |
统计分析
观看性别比例分析
上面我们将需要的信息都写入了comments.csv文件中,我们通过pandas来读取。在性别比例分析中,我们仅需要nickname和gender信息。
分析思路如下:
- 筛选dateframe,仅保留所需要的
nickname和gender信息 - 由于存在有人重复评论,需要先使用
drop_duplicates函数去重 - 通过
groupby函数,按照性别统计总数 - 画图
实现代码如下:
1 | def gender_analysis(gender_df): |
绘制结果:
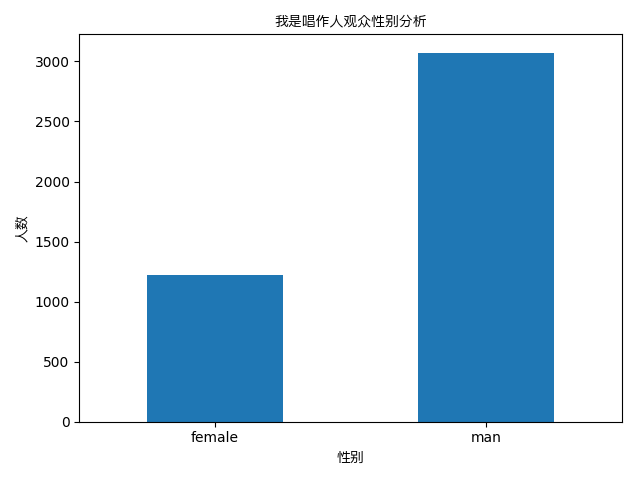
可见观看节目的男性要远多于女性。
评论分析及词云绘制
评论都保存在comment字段中,那么先获每条评论的内容,通过使用结巴分词进行逐行分词。为了提高分词处理效率,可以先对评论中的空格等进行剔除。主要思路如下:
- 获取一条评论,并替换空格等符号
- 通过结巴分词进行分词
- 提取分词中的名词部分并保存
- 计算保存的所有名词的频率
- 使用wordcloud第三方库绘制词云
实现如下:
1 | def extract_words(comment_df): |
绘制结果:

可见还是王源的呼声最高,其次汪苏泷、曾轶可、梁博。
拓展
完整代码和信息参考:https://github.com/keejo125/web_scraping_and_data_analysis/tree/master/iqiyi
